
热门







揭秘Unity的黑盒世界,“ShaderLab”底层原理浅谈

在阅读本文之前我们首先需要弄清楚什么是 ShaderLab?
ShaderLab是由Unity发明或者说是由Unity首创的一种语言体系,用来帮助大家做跨平台Shading开发。它里面除了语言规则之外,还有很多其他的东西。我们一个个来看。
我们先来看看ShaderLab Text(就是它的文本)。
我们大家知道,无论是写代码,还是写shading,实际上我们写的都是一堆文本。虽然在IDE 里看起来“花里胡哨”的,但是对计算机来讲就是文本。大家能看到,这就是我们非常熟悉的Unity的Shader,这个东西叫ShaderLab文本,是根据Unity定义的语法规则来写的。

我们可以看到,在基础文本里面会包含一些块,比如说Shader的名字,在Subshader里面也有它自己的属性,比如Tag、LOD等等。在Subshader下面还有一个个Pass,在Pass里面我们还可以定义不同的pragma、Vertex、Fragment,而其中的每个都对应着不同的代码块。
这是ShaderLab第一个组成的部分,我们称之为ShaderLab文本。
但光有文本是不行的,就如同你写C++,如果只是写了一堆CPP文件,依然是无法被计算机认可并执行的。中间需要有翻译的过程,这就是Shader Compiler的过程。如果大家在 Windows或者是Mac上有留意过的话,就会发现,打开Unity之后再打开任务管理器,或者在Mac上打开active monitor,你都会看到一个叫Unity shader Compiler的东西。如果是早期的Unity版本,你看到的就可能是cgbatch。

这个东西是干什么的呢?实际上它类似一种服务,是Unity在后台提供的一种服务,用来帮助我们去把写好的ShaderLab语言翻译为目标机器能够认可并执行的语言(我们会在下文中讲解大概是怎么翻译的)。
这是第二个组成模块。
第三个是一个体系,我们称之为ShaderLab Asset。我们写的ShaderLab大部分是不会进入到最终的运行环境中去的,需要经过二次加工。ShaderLab里面有很多东西都是不能直接使用的,需要进行翻译。而加工之后的东西,我们叫它Asset(资产),这个Asset比较常见的是这两个地方。

第一个地方,是我们打Assetbundle,这是大家最常见的,我们把shader 打成一个包,放到 bundle里。
还有一个就是在我们打出来包的Resources下面,会有level或者是 SharedAssets 这样的包,其实和Assetbundle的文件结构是很类似的,比如说场景里面直接引用的一些东西,大家既爱又恨的Always include Shader也在这里面。
这是两个Asset比较常见的地方。
但是有一个地方,大家不经常会用到。当我们在 library 文件夹里打开一个工程,就会看到一个叫 ShaderCache 的文件。我们在做预处理之后的中间产物,都会放到ShaderCache里面。
我们都知道Unity特别喜欢使用GUID做索引的,这个看起来和我们的library里面的data的东西很相似,也是一堆以数字或字母开头的文件夹,然而我们现在看到的这个也是ID但不是GUID。如果大家曾经拆过Unity AssetBundle,你会看到你写的代码。
你会经常看到整个从CGPROGRAM到ENDCG,在你的Asset里看不到了,变成了一个名字叫 GPU program IDXXX的文件,用一个ID索引了这一整段。在里面我们可以很简单地认为里面存的就是大家写的CG program中间的东西,当然不是直接存进去的,是经过了一系列的加工。这是我们存储几个shaderAsset的地方。
最后还有一个大家会经常遇到但是往往被忽略掉的事情——ShaderLab是有Runtime的。既然是一种有语法结构的语言,会包含很多的信息,Runtime能不能把这些信息利用起来就变得很重要。不然的话写了半天,打上Asset也没人用,就白白浪费掉了。
这个东西经常在哪儿见到呢?答案就是在Memory里面,如果你去使用一个Sample,你会在ShaderLab里面看到它。

这也是大家问题最集中的地方,为什么我ShaderLab这么大,到底是哪个Shader大?其实不是Shader大,而最有可能的是ShaderLab 整体很大。
所以整个Unity的ShaderLab大致分为四块,分别是由ShaderLab Text、shaderLab Compiler、shaderLab Asset以及shaderLab Runtime四个部分组合而成的。

我们了解了 ShaderLab 之后,再简单地看一下 ShaderLab 的工作流。
首先,当我们去做 Shader 的时候,第一步就是去写ShaderLab的Text,写完了之后干什么呢?写完之后你会发现,当你回到Unity的时候,Unity会开始有一个编译的过程,如果你第一次导入了很多的Shader,这个时候ShaderCompiler就开始工作了。
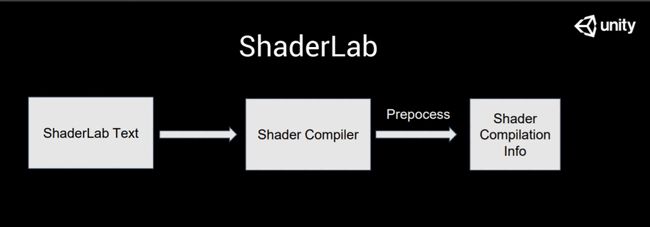
Unity的Shader 不是一次性编译到一个平台上的。
那么这个名为ShaderCache的东西,它是在什么时候产生的呢?其实在 shader被import进Unity系统的时候,Unity 会把原始的shader文本发给shaderCompiler去做一次预处理,预处理的结果并不是针对某一个平台最终的文本结构,这个时候编译出来的东西叫shader compilation info,是一个中间状态的一个信息集,这个信息集里面包含了很多重要的东西。以下是其中比较重要的几点:
第一,你的变体。我们知道 Unity 引入了 multi compile 和 shader feature 之后,通过一次编码就可以产生大量不同的 Shader。第一次我们去处理出变体的概念,是在我们做 Preprocess 的时候出现的。经过 Preprocess 第一次的处理,在 shader compilation info 里面,就已经把各个变体分开了。
当我们去把 shader compilation info 编译出来之后,会把相关的信息序列化,并且写到我们 ShaderCache 里面,这就是大家所看到的 ShaderCache。这个ShaderCache的信息会被用于我们后面的一些加速编译,不需要每次进入Unity都重新走一遍过程。当你的shader比较大,变体比较多的时候,Preprocess的过程是相对比较慢的。Preprocess的过程,如果我们更细化地说,实际上做了以下几件事情。
第一个是做语法分析,比如说我们解析语法数,就会生成词法解析器和语法解析器。我们先去做了一次语法解析和词法解析,当然在这个过程中Unity就会去检查大家的shader写得有没有问题,如果有报错,这个阶段就完成了。
当我们解析完了之后,Unity会把每一种不同的语言,从shader的文本中对应的部分切割出来。切割出来之后,再用对应的语言的Preprocess compile去做一遍对应这个语言的解析检查。通过这几次检查之后,最终我们会得到完整的compilation info,再把它写到ShaderCache 里面。
如果大家在去做一个Shader的时候,发现写完的这个Shader好像不太对,或者有点问题,你感觉没有进行重新编译,最简单的方法就是把ShaderCache删掉,然后再强行导入一次,重新编译一次,这时候问题就迎刃而解了。
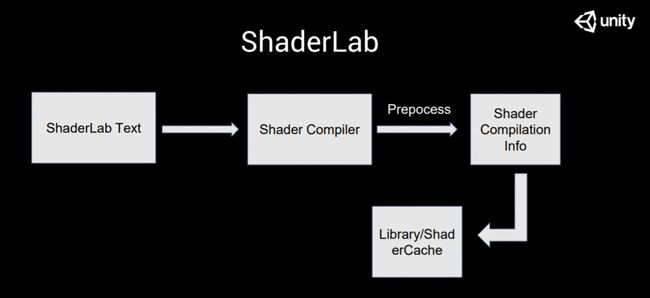
我们把它编出来,放到ShaderCache 里之后,这个时候只是Unity editor拿到了Compile 这个东西,但并不能用于渲染,也不能打到最终的包里。它只是Unity所使用的中间状态,如果是编译的话,大概就类似于IR的东西。
我们如何把它最终编译成可运行的版本呢?
我们可以从shader Compilation info,或者是ShaderCache里面找到相应的文件。这取决于你有没有,如果有的话,就能从shadercache里找到;如果没有的话,就会走一遍Prepocess的过程,再重新产生shader Compilation info。
拿到之后,我们会把这个东西再送到shader Compiler里面,再做一些其他的事情。这个 shader Compiler里面包含了很多不同的服务,刚才是Preprocess,这次我们要做的就是Binary Compile。这个事情会在以下几种情况下发生。

第一,我们现在启动了Unity。我们把资源都导入了,点击play。点的时候,Unity 会做一件叫Unity Editor warmup all shader的事情(当然在第一次导入的时候,Unity 也会做)。这就是为什么2020年之前的版本,大家在点开始的时候,会经常感觉到卡半天。实际上,“卡”的过程会把你内存里面,或者是资源里面所有shader的变体都warmup。但是真机上不会卡。
大家在去做一些性能检查,包括去研究原理的时候你会惊讶地发现,Unity 实际上是两个版本,运行时和编辑期是两套完全不同的东西。所以我们在做性能分析,或者是内存、CPU、GPU 分析的时候,不要在编辑器里面做。编辑器的设计目的是为了帮助大家以最流畅的速度去编辑,所以有很多的东西,不会去考虑运行时资源环境的占用,比如CPU或是内存的占用。Unity会默认认为你的电脑非常棒,内存不会爆,CPU不会卡,所以它可以尽情地挥霍这些资源,尽量保证大家整体的编辑体验是好的。但是在运行时,Unity会考虑实际的运行环境。比如手机和PC上的策略会有一些差异。
在这个地方我们进行 Binary Compile。
第二种情况,是真正开始打包了,比如说我们要给安卓打一个AssetBundle,或者发一个安卓的APK,这时候也会触发这个过程。总之触发这个过程的必要前提是我的目标平台是明确的,我知道要把中间的东西最终要翻译成什么。BinaryCompile 的过程其实是一个非常神奇的过程,Unity 实际上也不是直接把大家写的,比如说CG就直接翻译到目标平台上,这个工作量其实是很大的。
关于Unity的目标平台就非常多了,比如说大家常见的手机平台上有很多的API,加上主机平台,他们都有自己整套的语言规范。
大家可以脑补一下如果我们要是强行翻会怎样。这是一个乘的关系,左边4个,假如说右边是10个不同的平台,那就是40个,要写40套不同的代码,代码的路径就非常的缭乱。其一代码维护难度很大,其二是也很难写。
Unity使用了第三方技术,名为HLSLCC,CC的意思是交叉编译器,大家可以搜到。这个最终帮助Unity做出了一些优化和改变,和Unity使用的版本不是完全一样的(大家不要把网上的内容改一下直接替进来,这样行不通)。
Unity 实际上做了这样的工作:Unity会先把前端的一些语言,尽量地翻译到DX那个级别上去,通过DX的编辑器进行编辑,编辑完了之后,后端再走到HLSLCC,再向目标平台去输出,相当于是一个两步编译的过程。所以整体的难度降低了很多,大部分的工作是由HLSLCC来做的。
这个编译过程也会导致一个问题,比如DX里面没有,翻译不过去,中间要经过一步,其实就相当于过路费要交,但是过路的时候没有这个东西。因此Unity在2020以后的版本,最早的时候是用的DXBC,而现在用的则是DXRL,Unity也是基础于DX的编译器进行了自己的扩展,以便尽可能地去支持一些新特性。
电话:010-50951355 传真:010-50951352 邮箱:sales@souvr.com ;点击查看区域负责人电话
手机:13811546370 / 13720091697 / 13720096040 / 13811548270 /
13811981522 / 18600440988 /13810279720 /13581546145

